

Lista kodów odpowiedzi HTTP z wyjaśnieniami. Informacyjne (1xx), Powodzenia (2xx), Przekierowań (3xx), Błędów klienta (4xx) i Błędów serwera (5xx).
Spis treści
Skąd wiadomo, czy i kiedy serwer zrealizował zapytanie klienta? Czy istnieje sposób, by szybko i łatwo „komunikować” się z systemem, od którego wymaga się podjęcia określonych działań? Część internautów nawet się nad tym nie zastanawia. Oczekuje jedynie wyświetlania treści, których oczekują. Serwery natomiast bezustannie wysyłają do nich „wiadomości” najróżniejszych typów. Doskonałym tego przykładem są odpowiedzi HTTP. Mogą one występować w wielu rozmaitych formatach. Warto znać najważniejsze z nich, by wiedzieć, co się dzieje z realizacją zapytania. Dotyczy to zarówno właścicieli witryn, jak i samych internautów.
Czym są odpowiedzi HTTP?
Odpowiedzi HTTP są notatkami serwera HTTP, które zobaczyć można czasem na stronie internetowej. Nie są częścią witryny, przybierają natomiast charakter informacyjny. Ich krótka forma ma za zadanie uświadomić użytkownika na temat tego, co się stało, gdy przesłał zapytania do systemu. Najczęściej kojarzą się z występowaniem błędów w ładowaniu witryn. Nie pojawiają się jednak wyłącznie wtedy, gdy serwer odmawia zrealizowania zapytania. Są one bowiem zwracane zawsze, gdy przeglądarka nawiązuje kontakt z serwerem. Niektóre z nich po prostu nie są widoczne i nie utrudniają obsługi strony. Nie oznacza to jednak, że nie istnieją.
Poznanie odpowiedzi HTTP zgodnej z protokołem HTTP jest szczególnie istotne z punktu widzenia osób zarządzających witrynami WWW. Ich znajomość pozwala szybko zdiagnozować ewentualny problem. Przyśpiesza także naprawienie błędów konfiguracyjnych, jeśli takie wystąpiły. Ponadto można dzięki nim odpowiednio dbać o sprawne działanie swojego miejsca w sieci. Kodów odpowiedzi jest wiele, nie wszystkie jednak oczywiście pojawiają się z taką samą intensywnością. Podzielone są na pięć typów odpowiedzi. Zależą one od tego, czy i jak serwer zrozumiał zapytanie oraz jaka była na nie reakcja. Mowa tu zatem o kodach:
- informacyjnych,
- powodzenia,
- przekierowań,
- błędów klienta,
- błędów serwera.
Każda z tych grup charakteryzuje się licznymi rodzajami danych komunikatów. Poszczególne typy różnią się też strukturą liczbową. Już po tym możesz poznać, jaki charakter ma odpowiedź wskazanego serwera HTTP. W sumie spotkać możesz ponad 40 kodów. Na ekranie użytkownika pojawia się jednak zaledwie kilka z nich. Około kilkanaście z kolei uznać można za regularnie stosowane przez twórców witryn internetowych.
Pięć klas kodów odpowiedzi HTTP
100-199 – kody informacyjne
Kody informacyjne pojawiają się, gdy zapytanie zostało przyjęte, a jego realizacja jest kontynuowana. W zależności od żądanego zasobu i podjętych przez serwer działań, odpowiedzi mogą mieć kod:
- 100 – „Continue” – to odpowiedź wskazująca, że żądanie jest kontynuowane. Jeśli natomiast zostało już zakończone, można ją zignorować.
- 101 – „Switching Protocols” – odpowiedź wskazująca, na który protokół przełącza się serwer;
- 103 – „Early Hints„ – odpowiedź wskazująca na wstępne ładowanie zasobów w czasie, gdy serwer przygotowuje odpowiedź do danego zapytania;
- 110 – „Connection Timed Out” – odpowiedź pojawiająca się, gdy czas obsłużenia danego zapytania zostanie przekroczony, a serwer zbyt długo nie odpowiada;
- 111 – „Connection Refused” – odrzucenie połączenia przez serwer.
200-299 – kody powodzenia
Kody powodzenia wskazują, że żądanie zasobu zostało pomyślnie przyjęte. System je zrozumiał i poprawnie zrealizował. Zależnie od charakteru zapytania klienta, w tej grupie spotkać można kody:
- 200 – „OK” – to najczęściej zwracany nagłówek odpowiedzi HTTP w komunikacji online. Wskazuje, że oczekiwana odpowiedź została zwrócona przez serwer. Oznacza poprawne działanie strony internetowej czy zasobu;
- 201 – „Created” – dokument wysyłany przez użytkownika na serwer został zapisany poprawnie;
- 202 – „Accepted” – oznaka przyjęcia zapytania do obsłużenia. Jego realizacja natomiast jeszcze się nie zakończyła;
- 203 – „Non-Authoritative Information – odpowiedź pierwotnego serwera i zwrócona informacja różnią się. Ta ostatnia została utworzona z lokalnych lub zewnętrznych kopii;
- 204 – „No content” – doszło do realizacji żądania klienta. Nie ma potrzeby zwracania żadnej treści;
- 205 – „Reset Content” – zapytanie zostało zrealizowane przez serwer. Pierwotny wygląd dokumentu powinien zostać przywrócony przez klienta;
- 206 – „Partial Content” – tylko część zapytania typu GET została zrealizowana przez serwer.
300-399 – kody przekierowań
Kody przekierowań oznaczają, że żądany zasób zastąpił określoną zawartość. Wyróżnić w tym segmencie można:
- 300 – „Multiple Choices” – pojawia się, gdy istnieje kilka sposobów obsługi wskazanej aktywności. W takiej sytuacji serwer może podać adres zasobu pozwalającego wybrać jednoznaczne zapytanie;
- 301 – „Moved Permanently” – oznacza, że został zmieniony adres zasobu. Wskazuje, pod jakim, nowym adresem, można szukać go w przyszłości;
- 302 – „Found” – gdy zasób chwilowo widnieje pod innym adresem. W przyszłości odwołania będą kierowane pod pierwotny adres;
- 303 – „See Other” – właściwy sposób przekierowywania, gdy wystosowane zostało żądanie metodą POST. Oznacza, że klient powinien skierować się pod inny adres, bo tam znajduje się odpowiedź, której szuka;
- 304 – „Not Modified” – wskazuje, że oczekiwany zasób nie uległ zmianie, biorąc pod uwagę warunek wskazany przez klienta (np. przy dacie ostatniej pobieranej wersji danych);
- 305 – „Use Proxy” – oznacza, że zapytanie realizuje serwer proxy podany w nagłówku;
- 306 – „Switch Proxy” – kod zastrzeżony dla starszych wersji protokołu, obecnie nieużywany;
- 307 – „Temporary Redirect” – zasób chwilowo znajduje się pod innym adresem. Odpowiedź musi zawierać zmieniony adres zasobu. Klient zobowiązany jest przenieść się na niego;
- 308 – „Permanent Redirect” – używany, gdy żądany zasób zostanie trwałe przeniesiony na nowy adres URL. Przeglądarka jest przekierowana w nowe miejsce, podobnie jak roboty Google;
- 310 – „Too many redirects” – wskazuje na zbyt dużą liczbę przekierowań.
400-499 – kody błędów klienta
Kody błędów klienta informują o tym, że wystąpił problem z żądaniem wystosowanym przez internautę. To najbardziej rozbudowana i różnorodna grupa odpowiedzi:
- 400 – „Bad Request” – w wyniku nieprawidłowości w formie błędu użytkownika (np. błędna składnia zapytania) serwer nie może obsłużyć żądania;
- 401 – „Unauthorized” – wskazuje, że żądany zasób wymaga uwierzytelnienia;
- 402 – „Payment Required” – kod, z którego korzysta Google Developers API, zarezerwowany na przyszłość. Wskazuje, że dany programista przekroczył dzienny limit zapytań;
- 403 – „Forbidden” – pytanie zostało zrozumiane, ale konfiguracja bezpieczeństwa zabrania serwerowi zwrócić dany zasób (np. WAF typu ModSecurity);
- 404 – „Not Found” – zasób nie został odnaleziony na podstawie adresu. Co więcej, serwer nie odnalazł nic, co mogłoby wskazywać, że dana informacja istniała w przeszłości;
- 405 – „Method Not Allowed” – występuje, gdy żądanie zawiera metodę niedozwoloną dla danego zasobu;
- 406 – „Not Acceptable” – wskazuje, że według informacji z zapytania, zażądany zasób nie może zwrócić odpowiedzi, która mogłaby zostać obsłużona;
- 407 – „Proxy Authentication Required” – dotyczy dostępu do proxy. Wskazuje na konieczność uwierzytelnienia do serwera pośredniczącego;
- 408 – „Request Timeout” – gdy klient nie wystosuje zapytania do serwera w określonym czasie;
- 409 – „Conflict” – gdy występuje konflikt z obecnym statusem zasobu i żądanie nie może zostać zrealizowane. Występuje, gdy klient ma szansę odnaleźć przyczyny błędu i przesłać ponownie prawidłowe zapytanie;
- 410 – „Gone” – żądany zasób nie jest już dostępny;
- 411 – „Length Required” – zapytanie nie jest realizowane przez serwer, bo nie ma w nim nagłówka „Content-Lenght”;
- 412 – „Precondition Failed” – gdy co najmniej jeden z warunków z zapytania nie może zostać spełniony przez serwer;
- 413 – „Request Entity Too Large” – zapytanie jest zbyt długie;
- 414 – „Request-URI Too Long” – żądany adres URL jest zbyt długi;
- 415 – „Unsupported Media Type” – serwer odmawia przyjęcia zapytania. Powodem jest jego niezrozumiała składnia;
- 416 – „Requested Range Not Satisfiable” – w zapytaniu jest zakres, którego nie da się zastosować do danego zasobu;
- 417 – „Expectation Failed” – oczekiwanie podane w żądaniu nie może zostać spełnione przez serwer;
- 418 – „I’m a teapot” – tzw. easter egg o charakterze humorystycznym. Zwykle nieimplementowany obecnie do serwerów HTTP;
- 421 – „Misdirected Request” – gdy zapytanie trafi do serwera niewłaściwego lub takiego, który nie może na nie odpowiedzieć;
- 422 – „Unprocessable entity” – gdy zapytanie nie może być kontynuowane przez zawarte w nim błędy semantyczne;
- 423 – „Locked (WebDAV)” – zasób jest aktualnie zablokowany;
- 424 – „Failed Dependency (WebDAV)” – żądanie, od którego zależnie jest wydane polecenie, nie powiodło się;
- 425 – „Too Early” – żądanie nie zostaje przetworzone przez serwer z uwagi na zagrożenie atakiem typu Replay;
- 426 – „Upgrade Required” – żądanie nie zostaje wykonane przez serwer przy użyciu wykorzystanego protokołu. Poprawny zostaje przekazany w nagłówku „Upgrade”;
- 428 – „Precondition Required” – gdy zabraknie wymaganego przez serwer nagłówka wstępnego;
- 429 – „Too Many Requests” – gdy przez użytkownika zostało wysłanych zbyt wiele żądań w danym czasie;
- 431 – „Request Header Fields Too Large” – gdy pole (lub pola) nagłówka są zbyt duże;
- 451 – „Unavailable For Legal Reasons” – zawartość strony jest niedostępna z uwagi na naruszenie prawa;
- 499 – „Client Closed Request” – żądanie nie może zostać wykonane, ponieważ klient (najcześciej przeglądarka) zakończył połączenie.
500-599 – kody błędu serwera HTTP
Kody błędów serwera HTTP oznaczają, że żądanie zostało zaakceptowane. Wystąpienie błędu na serwerze sprawiło jednak, że ostatecznie nie zostało ono spełnione. Przybierać mogą kilka różnych form:
- 500 – „Internal Server Error” – serwer napotkał niespodziewane trudności. Uniemożliwiły one realizację żądania;
- 501 – „Not Implemented” – kod zwracany w momencie, gdy serwer otrzymuje nieznany typ zapytania;
- 502 – „Bad Gateway” – serwer pośredniczący otrzymał nieprawidłową odpowiedź od serwera nadrzędnego. Z tego powodu nie jest w stanie zrealizować żądania;
- 503 – „Service Unavailable” – ze względu na przeciążenie, serwer nie może zrealizować zapytania w danym momencie;
- 504 – „Gateway Timeout” – serwer pośredniczący w odpowiednim czasie nie otrzymał odpowiedzi od serwera wskazanego, potrzebnej do realizacji żądania;
- 505 – „HTTP Version Not Supported” – wskazana przez klienta wersja HTTP nie może być obsłużona przez serwer;
- 506 – „Variant Also Negotiates” – wewnętrzny błąd konfiguracji serwera;
- 507 – „Insufficient Storage (WebDAV)” – dane związane z wykonaniem zapytania nie mogą zostać zapisane przez serwer;
- 508 – „Loop Detected (WebDAV)” – w trakcie przetwarzania zapytania serwer wykrył nieskończoną pętlę;
- 509 – „Bandwidth Limit Exceeded” – właściciel serwera przekroczył limit transferu danych, przez co jest on obecnie niedostępny;
- 510 – „Not Extended” – brakuje rozszerzenia HTTP niezbędnego do obsługi żądania;
- 511 – „Network Authentication Required” – przed otrzymaniem dostępu do sieci wymagane jest uwierzytelnienie.
Jak znaleźć kod odpowiedzi serwera?
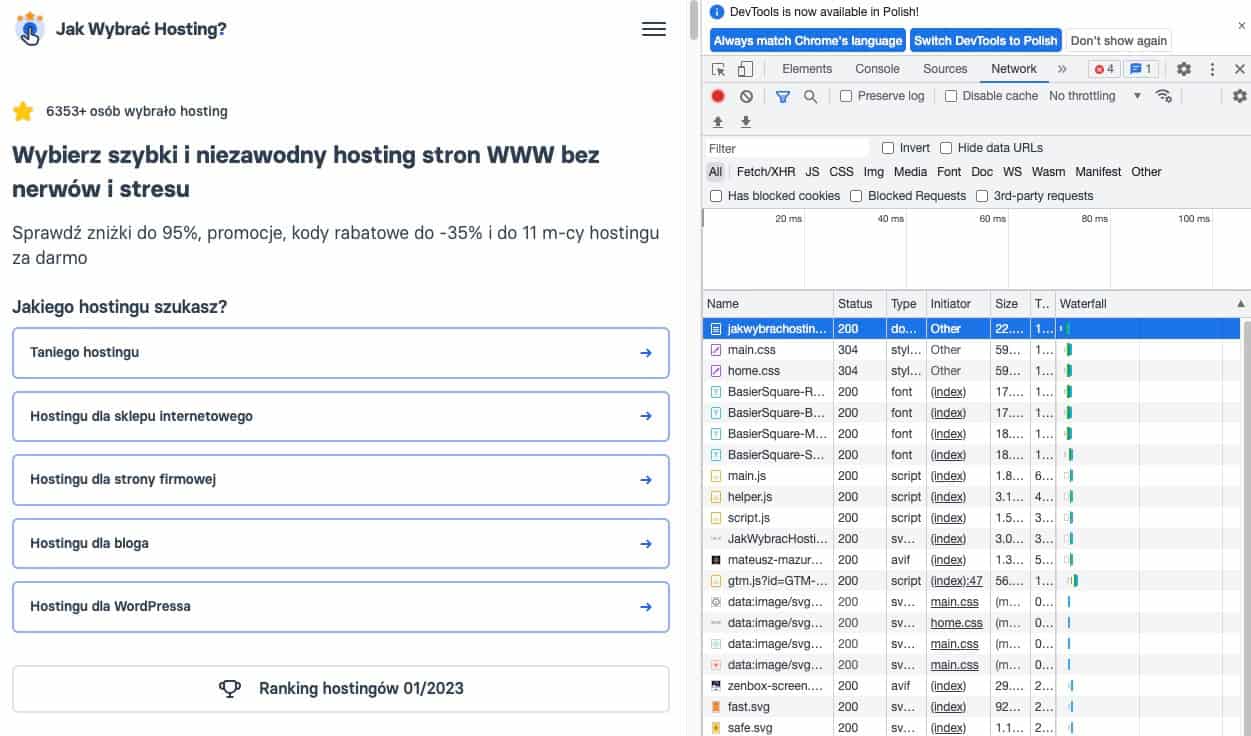
Odnalezienie kodu odpowiedzi serwera możliwe jest na wiele sposobów. W przypadku pojedynczej strony najłatwiej jest zrobić to z poziomu przeglądarki internetowej. Zależnie od programu, którego używasz na co dzień, procedura może wyglądać nieco inaczej. Na przykładzie Google Chrome wystarczy natomiast tylko:
- nacisnąć przycisk F12;
- wybrać zakładkę „Network”;
- wpisać adres strony internetowej.
Kod odpowiedzi znajduje się w sektorze „Status”. W przypadku naszej strony jakwybrachosting.pl jest to kod 200. Oznacza to, że żądanie wyświetlenia witryny zostało zrealizowane poprawnie. Poniżej prezentujemy, w którym miejscu znajdziesz potrzebną Ci informację. Otwierane okno wygląda bardzo podobnie w każdej witrynie internetowej.
Chcesz sprawdzić większą liczbę stron? Możesz do tego użyć również wielu darmowych programów i narzędzi. Jednym z najpopularniejszych jest Screaming Frog SEO Spider. Bez problemu przeskanujesz w nim nawet do 500 adresów URL. Listę błędów z kolei możesz wyeksportować tam np. do pliku .xls. To dobre rozwiązanie dla osób zajmujących się obsługą witryn internetowych w profesjonalny sposób.
Kody odpowiedzi HTTP a pozycjonowanie w sieci
Kody odpowiedzi HTTP są ważne nie tylko z perspektywy właściciela, administratora i użytkownika strony. Mają także ogromne znaczenie dla procesu pozycjonowania danej witryny. Należy tu bowiem uświadomić sobie, że każdy problem z jej wyświetlaniem może zostać zarejestrowany przez Googleboty. Efektem tego bywa z kolei spadek jej widoczności w internecie.
Co robią algorytmy Google? Ich zadaniem jest upewnianie się, że żądania użytkowników w danym miejscu w sieci są szybko i prawidłowo realizowane. Zgodnie ze wskazaniami, przekierowania np. śledzone są do 10. Jeśli natomiast potrzebnych jest ich więcej, określane są jako błąd. W ten sposób roboty są w stanie ocenić, która witryna „dobrze traktuje” odbiorców. Jeśli tego nie robi, to może zostać „ukarana” słabszym miejscem w wynikach wyszukiwania.
Niekorzystnie na sytuację witryny wpływają oczywiście również rozmaite błędy. Dobrym przykładem są tu kody z grup 400-499 i 500-599. Występowanie tych odpowiedzi może sprawić, że strony te nie zostaną poprawnie zaindeksowane. W efekcie tego witryna nie będzie pojawiać się w wyszukiwarce Google. To z kolei przełoży się na to, że nie będą jej odwiedzać użytkownicy. Brak ruchu to brak klientów, a więc i zysków. Właśnie z tego powodu dbanie o odpowiednie przekierowania i usuwanie błędów jest tak ważne.
Dlaczego pojawiają się błędy HTTP?
Gdy wpisujesz adres w wyszukiwarce lub klikasz na link, Twoja przeglądarka kontaktuje się z serwerem. Wysyła mu żądanie, które on następnie odbiera i przetwarza. Jeśli wszystko idzie zgodnie z planem, w odpowiedzi na nie odsyłane są pożądane dane w nagłówku HTTP. Zachowanie serwera natomiast opisuje właśnie kod HTTP.
Pojawiają się one zawsze, choć większość internautów zauważa tylko niektóre. Najczęściej widać błędy, bo one pojawić się mogą na ekranie użytkownika, zamiast oczekiwanej zawartości. Dzieje się tak, gdy serwer nie był w stanie spełnić Twojego polecenia. Wyświetla on wtedy odpowiedni komunikat – w formie 3-cyfrowego kodu. Ma on Cię poinformować, że polecenie nie zostanie spełnione. Odpowiedź taka zawiera także informację o przyczynie takiego stanu rzeczy. Zależnie od zdarzenia, użytkownik czasem może to w określony sposób spróbować naprawić, np. zmieniając żądanie.